






随着信息技术发展的突飞猛进,信息化审计的地位日益凸显,而数据审计作为信息化审计的重要组成部分,其审计技术和方法的创新决定着信息化审计工作的成效。
根据审计署发布的数据审计指南对数据审计的定义,数据审计是指审计机关通过数据准备和数据分析进行审计的行为。这实际上指出了数据审计的两个重要内容,即数据准备和数据分析。信息技术的飞速发展随之也带来了信息爆炸的问题,对数据审计的影响体现在工作中需要处理的数据几近指数增长,而且随着审计监督全覆盖的推进,该问题将愈加明显。如何对这些海量数据进行整理并加以分析从中发现审计线索,成为一个亟待解决的问题。
一、ETL技术及实现
ETL,是 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL常用于数据仓库领域,目的是将分散、零乱、标准不统一的数据,按照统一的规则进行集成整合,完成数据从数据源向目标数据仓库的转化。
ETL的实现一般有三种方式:一是借助ETL工具。典型的ETL工具有IBM InfoSphere DataStage(以下简称DataStage),Oracle Warehouse Builder,Microsoft SQL Server DTS等,借助ETL工具可以快速的建立起ETL工程,屏蔽掉复杂的编码工作,使ETL开发专注于逻辑规则的实现,提升开发的效率,但纯粹借助工具缺乏灵活性。二是通过SQL脚本来实现。这种方式的最大优点是处理灵活,能够最大程度上体现ETL开发人员的思路,但同时该方式对ETL开发人员技术要求高,编写脚本难度大。三是上述两种方式的结合。通过将ETL工具与SQL脚本方式结合,可以提高ETL开发效率的同时又不失灵活性,实际上目前部分ETL工具中已经提供了可供开发人员编写SQL处理脚本的模块,技术上实现了前两种方式的结合。
二、ETL工具的应用
通过上述对ETL技术的介绍,我们可以发现,对审计数据的采集、整理并标准化是一个典型的ETL技术应用场景,而且将审计数据库建设成面向主题的、集成的、稳定的和反映历史变化的数据仓库,供数据审计进行联机分析处理和提供决策支持,也应成为今后的一个努力方向。
下面笔者结合单位使用的DataStage软件浅谈ETL技术在数据审计中的应用。
(一)DataStage的工作模式
DataStage是通过设计job来实现ETL功能的,job的设计与普通的IDE设计工具类似,通过拖拽控件(stage)并添加脚本来完成。DataStage提供了种类功能繁多的控件,将不同功能的控件按照数据处理的需求通过一定方式加以组合,形成job进行编译运行,从而实现对数据的抽取转换加载(图1-DataStage开发设计界面)。DataStage除使用图形化界面开发,易于操作和维护管理外,还具有支持异构数据库、采用并行机制提高数据处理速度、减少源数据库服务器压力以及支持自定义开发组件等优点。
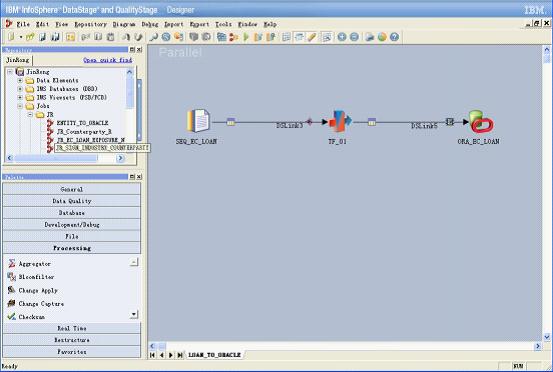
图1-DataStage开发设计界面
(二)数据准备中的应用
数据准备阶段包括对审计对象的数据进行采集、整理、加工,最终形成便于审计人员开展数据分析的基础。
目前审计工作中从审计对象采集的后台数据主要包括Oracle数据库文件、SQL SERVER数据库文件以及EXCEL、TXT文本文件等,DataStage对这些常见的数据源均有相应的组件进行支持。假设Oracle数据库文件、SQL SERVER数据库文件已经在相应的数据库系统中完成了恢复,在Datastage中使用前只需先进行ODBC配置,然后在开发时选择相应的源数据组件Oracle Connector、ODBC Connector即可。除Oracle和SQL SERVER外,Datastage还支持DB2、Sysbase等数据库(图2-DataStage部分数据库组件)。EXCEL和TXT文本文件也可以调用Sequence File Stage和Unstructured Data Stage进行数据读取。

图2-DataStage部分数据库组件
接下来是数据的整理和标准化工作,即ETL中的清洗和转换数据。数据清洗的主要目的是为了过滤不符合要求的数据,根据过滤结果由业务人员判断直接删除或是由数据提供单位补充修正后重新抽取。不符合要求的数据主要包括不完整的数据、错误数据和重复数据。不完整的数据主要指数据中部分应有的信息缺失,如工商数据中的股东持股比例信息缺失、银行流水数据中的对手信息缺失等,DataStage中可以使用Transformer组件调用内置函数IsNull对空值数据进行筛选;错误数据主要指因业务系统不健全,在数据录入时没有经过检验检查直接写入数据库后导致的数据错误,如应为数字格式的金额字段填入了文字,日期格式的字段值录入不规范等,同样可以使用Transformer组件调用参数类型匹配函数IsValid进行匹配,更复杂的逻辑可以开发自定义函数Routines来处理;重复数据则是指出现了一个或多个字段值重复的情况,这种情况可使用Remove Duplicates Stage直接对数据去重复记录。
完成数据的清洗后,最后按照一定的规则,将数据进行转换,形成便于数据分析人员使用的标准表。数据的转换主要包括表连接、合并、排序等,Datastage都提供了相应的功能组件Join、Merge、Sort等来完成这一工作(图3-DataStage部分数据处理组件),Transformer组件也可以通过调用一系列内置函数和自定义函数来完成数据的转换。
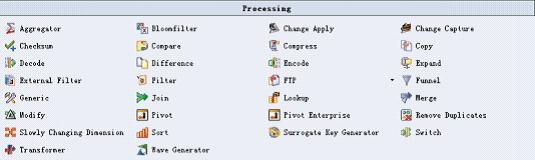
图3-DataStage部分数据处理组件
图4描述了将某银行业务数据中的几张表按照标准化规则进行相应的连接、去重和转换后形成便于数据分析人员使用的标准表的ETL开发模型。
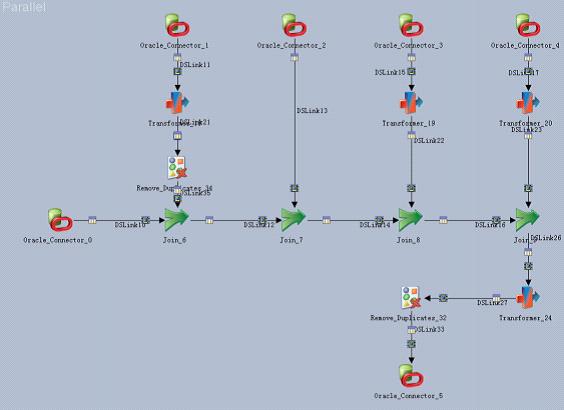
图4-某银行数据标准化的ETL模型
(三)数据分析中的应用
鉴于Datastage的对数据的转换提供了丰富的内置组件、功能函数并支持自定义开发组件,推而广之,完全可以利用这些组件尤其是自定义开发组件来实现数据分析方法,将ETL开发演化成审计方法或审计模型的开发,特别是对于一些结构固定的业务数据,如财政收支数据、税收征管数据、银行业务数据等,可以根据日常工作总结的常规性审计思路进行ETL开发形成一套固定的审计模型,针对不同时间或地域范围的数据,只需稍微修改模型参数后在软件中编译运行即可得到数据分析结果,实现了审计方法的模块化和重用化,简化了数据分析的过程,降低了数据分析的技术难度,从而大大提高数据分析的效率。(张立)
| 【关闭】 【打印】 |



